Dialogue Bot for goal-oriented task¶
There are available two pretrained models for DSTC2 dataset (English). Try them by running:
from deeppavlov import build_model, configs
bot1 = build_model(configs.go_bot.gobot_dstc2, download=True)
bot1(['hi, i want restaurant in the cheap pricerange'])
bot1(['bye'])
bot2 = build_model(configs.go_bot.gobot_dstc2_best, download=True)
bot2(['hi, i want chinese restaurant'])
bot2(['bye'])
If some required packages are missing, install all the requirements by running in command line:
python -m deeppavlov install gobot_dstc2
Intro¶
The dialogue bot is based on [1] which introduces Hybrid Code Networks (HCNs) that combine an RNN with domain-specific knowledge and system action templates.
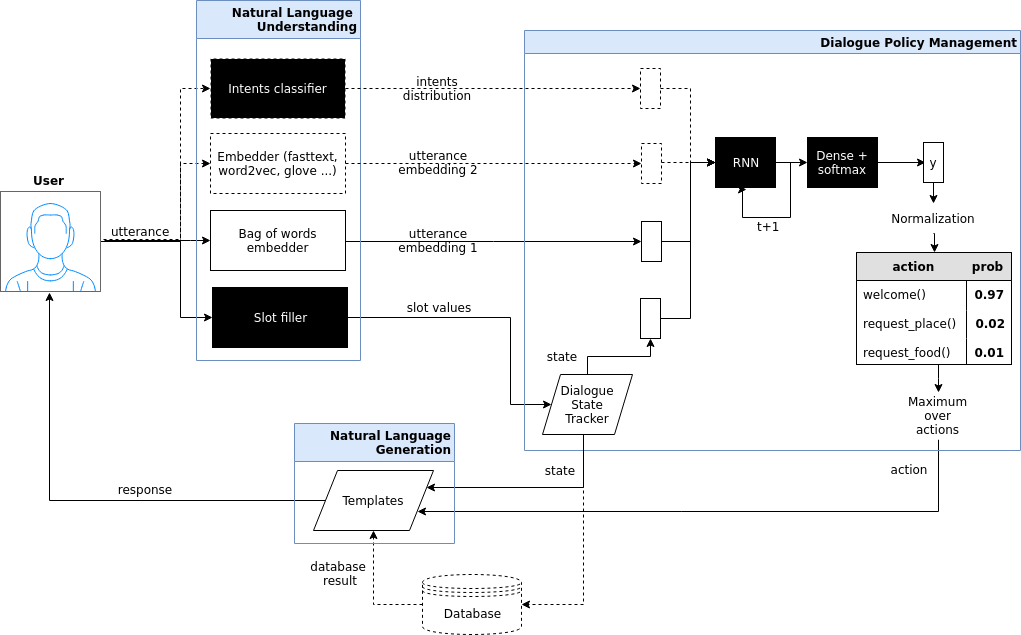 Diagram 1. Dotted lines correspond to unrequired
(optional) modules, black squares to trained models, trapezes are
modules that depend on a dataset and must be provided by software
developer.
Diagram 1. Dotted lines correspond to unrequired
(optional) modules, black squares to trained models, trapezes are
modules that depend on a dataset and must be provided by software
developer.
Here is a simple example of interaction with a trained dialogue bot (available for download):
Note
Models that rely on fasttext word embeddings will require 8.5 GB of disk space, those that use only one-hot encoding of words will require less than 300Mb of disk space.
>> Hello, welcome to the Cambridge restaurant system. You can ask for restaurants by area, price range or food type. How may I help you?
x::hi, i want cheap food
2018-05-16 12:28:48.459 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'cheap'}, got 22 results.
>> The lucky star serves chinese food in the cheap price range.
x::is there anything with french food?
2018-05-16 12:29:02.795 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'cheap', 'food': 'french'}, got 0 results.
>> Sorry there is no french restaurant in the cheap price range.
x::ok, maybe there is something in expensive pricerange?
2018-05-16 12:29:23.337 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'expensive', 'food': 'french'}, got 2 results.
>> Cote serves french food in the expensive price range.
x::in what part of town is it?
2018-05-16 12:29:31.193 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'expensive', 'food': 'french'}, got 2 results.
>> Restaurant two two is a nice place in the north of town serving tasty french food.
x::ok, give me their phone number
>> The phone number of restaurant two two is 01223 351880.
x::address and post code too
>> Restaurant two two is on 22 chesterton road chesterton, c.b 4, 3 a.x.
x::ok, thank you!
>> Restaurant two two serves french food in the expensive price range.
x::and if i wanted an italian restuarant?
2018-05-16 12:30:15.98 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'expensive', 'food': 'italian'}, got 4 results.
>> Frankie and bennys serves italian food in the expensive price range.
x::more cheaply priced?
2018-05-16 12:30:36.560 INFO in 'deeppavlov.models.go_bot.bot'['bot'] at line 346: Made api_call with {'pricerange': 'cheap', 'food': 'italian'}, got 5 results.
>> Da vinci pizzeria serves italian food in the cheap price range.
x::ok, give me their phone number and address, please
>> The phone number of da vinci pizzeria is 01223 351707 and it is on 20 milton road chesterton.
x::thanks
>> Da vinci pizzeria serves italian food in the cheap price range.
x::bye
>> You are welcome!
Usage¶
Requirements¶
TO TRAIN a go_bot model you should have:
(optional, but recommended) pretrained named entity recognition model (NER)
- config configs/ner/slotfill_dstc2.json is recommended
(optional, but recommended) pretrained intents classifier model
- config configs/classifiers/intents_dstc2_big.json is recommended
(optional) any sentence (word) embeddings for english
fasttext embeddings can be downloaded
- via link https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.en.zip
- or using deeppavlov with
python3 -m deeppavlov download <path_to_config>, where<path_to_config>is one of the provided config files.
TO INFER from a go_bot model you should additionally have:
- pretrained vocabulary of dataset utterance tokens
- it is trained in the same config as go_bot model
- pretrained goal-oriented bot model
- config configs/go_bot/gobot_dstc2.json is recommended
slot_fillersection of go_bot’s config should match NER’s configurationintent_classifiersection of go_bot’s config should match classifier’s configuration
Configs:¶
For a working exemplary config see configs/go_bot/gobot_dstc2.json (model without embeddings).
A minimal model without slot_filler, intent_classifier and embedder is configured
in configs/go_bot/gobot_dstc2_minimal.json.
The best state-of-the-art model (with attention mechanism, relies on embedder and
does not use bag-of-words) is configured in
configs/go_bot/gobot_dstc2_best.json.
Usage example¶
To interact with a pretrained go_bot model using commandline run:
python -m deeppavlov interact <path_to_config> [-d]
where <path_to_config> is one of the provided config files.
You can also train your own model by running:
python -m deeppavlov train <path_to_config> [-d]
The -d parameter downloads
- data required to train your model (embeddings, etc.);
- a pretrained model if available (provided not for all configs).
Pretrained for DSTC2 models are available for
After downloading required files you can use the configs in your python code.
To infer from a pretrained model with config path equal to <path_to_config>:
from deeppavlov import build_model
CONFIG_PATH = '<path_to_config>'
model = build_model(CONFIG_PATH)
utterance = ""
while utterance != 'exit':
print(">> " + model([utterance])[0])
utterance = input(':: ')
Config parameters¶
To configure your own pipelines that contain a "go_bot" component, refer to documentation for GoalOrientedBot and GoalOrientedBotNetwork classes.
Datasets¶
DSTC2¶
The Hybrid Code Network model was trained and evaluated on a modification of a dataset from Dialogue State Tracking Challenge 2 [2]. The modifications were as follows:
- new turns with api calls
- added api_calls to restaurant database (example:
{"text": "api_call area=\"south\" food=\"dontcare\" pricerange=\"cheap\"", "dialog_acts": ["api_call"]})
- added api_calls to restaurant database (example:
- new actions
- bot dialog actions were concatenated into one action (example:
{"dialog_acts": ["ask", "request"]}->{"dialog_acts": ["ask_request"]}) - if a slot key was associated with the dialog action, the new act
was a concatenation of an act and a slot key (example:
{"dialog_acts": ["ask"], "slot_vals": ["area"]}->{"dialog_acts": ["ask_area"]})
- bot dialog actions were concatenated into one action (example:
- new train/dev/test split
- original dstc2 consisted of three different MDP policies, the original train and dev datasets (consisting of two policies) were merged and randomly split into train/dev/test
- minor fixes
- fixed several dialogs, where actions were wrongly annotated
- uppercased first letter of bot responses
- unified punctuation for bot responses
See deeppavlov.dataset_readers.dstc2_reader.DSTC2DatasetReader for implementation.
Your data¶
Dialogs¶
If your model uses DSTC2 and relies on "dstc2_reader"
(DSTC2DatasetReader),
all needed files, if not present in the
DSTC2DatasetReader.data_path directory,
will be downloaded from web.
If your model needs to be trained on different data, you have several ways of achieving that (sorted by increase in the amount of code):
- Use
"dialog_iterator"in dataset iterator config section and"dstc2_reader"in dataset reader config section (the simplest, but not the best way):- set
dataset_reader.data_pathto your data directory; - your data files should have the same format as expected in
DSTC2DatasetReader.read()method.
- set
- Use
"dialog_iterator"in dataset iterator config section and"your_dataset_reader"in dataset reader config section (recommended):- clone
deeppavlov.dataset_readers.dstc2_reader.DSTC2DatasetReadertoYourDatasetReader; - register as
"your_dataset_reader"; - rewrite so that it implements the same interface as the origin.
Particularly,
YourDatasetReader.read()must have the same output asDSTC2DatasetReader.read().train— training dialog turns consisting of tuples:- first tuple element contains first user’s utterance info
(as dictionary with the following fields):
text— utterance stringintents— list of string intents, associated with user’s utterancedb_result— a database response (optional)episode_done— set totrue, if current utterance is the start of a new dialog, andfalse(or skipped) otherwise (optional)
- second tuple element contains second user’s response info
text— utterance stringact— an act, associated with the user’s utterance
- first tuple element contains first user’s utterance info
(as dictionary with the following fields):
valid— validation dialog turns in the same formattest— test dialog turns in the same format
- clone
- Use your own dataset iterator and dataset reader (if 2. doesn’t work for you):
- your
YourDatasetIterator.gen_batches()class method output should match the input format for chainer from configs/go_bot/gobot_dstc2.json.
- your
Templates¶
You should provide a maping from actions to text templates in the format
action1<tab>template1
action2<tab>template2
...
actionN<tab>templateN
where filled slots in templates should start with “#” and mustn’t contain whitespaces.
For example,
bye You are welcome!
canthear Sorry, I can't hear you.
expl-conf_area Did you say you are looking for a restaurant in the #area of town?
inform_area+inform_food+offer_name #name is a nice place in the #area of town serving tasty #food food.
It is recommended to use "DefaultTemplate" value for template_type parameter.
Database (optional)¶
If your dataset doesn’t imply any api calls to an external database, just do not set
database and api_call_action parameters and skip the section below.
Otherwise, you should
provide sql table with requested items or
construct such table from provided in train samples
db_resultitems. This can be done with the following script:python -m deeppavlov train configs/go_bot/database_<your_dataset>.json
where
configs/go_bot/database_<your_dataset>.jsonis a copy ofconfigs/go_bot/database_dstc2.jsonwith configuredsave_path,primary_keysandunknown_value.
Comparison¶
Scores for different modifications of our bot model:
| Model | Config | Test turn textual accuracy |
|---|---|---|
| basic bot | gobot_dstc2_minimal.json | 0.3809 |
| bot with slot filler & fasttext embeddings | 0.5317 | |
| bot with slot filler & intents | gobot_dstc2.json | 0.5248 |
| bot with slot filler & intents & embeddings | 0.5145 | |
| bot with slot filler & embeddings & attention | gobot_dstc2_best.json | 0.5551 |
There is another modification of DSTC2 dataset called dialog babi Task6 [3]. It differs from ours in train/valid/test split and intent/action labeling.
These are the test scores provided by Williams et al. (2017) [1] (can’t be directly compared with above):
| Model | Test turn textual accuracy |
|---|---|
| Bordes and Weston (2016) [4] | 0.411 |
| Perez and Liu (2016) [5] | 0.487 |
| Eric and Manning (2017) [6] | 0.480 |
| Williams et al. (2017) [1] | 0.556 |
TODO: add dialog accuracies
References¶
| [1] | (1, 2, 3) Jason D. Williams, Kavosh Asadi, Geoffrey Zweig “Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning” – 2017 |
| [2] | Dialog State Tracking Challenge 2 dataset |
| [3] | The bAbI project |
| [4] | Antoine Bordes, Y-Lan Boureau & Jason Weston “Learning end-to-end goal-oriented dialog” - 2017 |
| [5] | Fei Liu, Julien Perez “Gated End-to-end Memory Networks” - 2016 |
| [6] | Mihail Eric, Christopher D. Manning “A Copy-Augmented Sequence-to-Sequence Architecture Gives Good Performance on Task-Oriented Dialogue” - 2017 |