Syntactic parsing¶
Syntactic parsing is the task of prediction of the syntactic tree given the tokenized (or raw) sentence. The typical output of the parser looks looks like
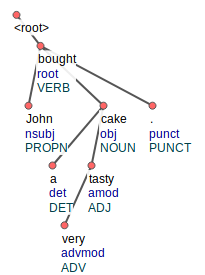
To define a tree, for each word one should know its syntactic head and the dependency label for the edge between them. For example, the tree above can be restored from the data
1 John 2 nsubj
2 bought 0 root
3 a 6 det
4 very 5 advmod
5 tasty 6 amod
6 cake 2 obj
7 . . 2 punct
Here the third column contains the positions of syntactic heads and the last one – the dependency labels. The words are enumerated from 1 since 0 is the index of the artificial root of the tree, whose only dependent is the actual syntactic head of the sentence (usually a verb).
Syntactic trees can be used in many information extraction tasks. For example, to detect who is the winner and who is the loser in the sentence Manchester defeated Liverpool one relies on the word order. However, many languages, such as Russian, Spanish and German, have relatively free word order, which means we need other cues. Note also that syntactic relations (nsubj, obj and so one) have clear semantic counterparts, which makes syntactic parsing an appealing preprocessing step for the semantic-oriented tasks.
Model usage¶
Before using the model make sure that all required packages are installed using the command:
python -m deeppavlov install syntax_ru_syntagrus_bert
Our model produces the output in CONLL-U format and is trained on Universal Dependency corpora, available on http://universaldependencies.org/format.html . The example usage for inference is
from deeppavlov import build_model, configs
model = build_model(configs.syntax_parser.syntax_ru_syntagrus_bert, download=True)
sentences = ["Я шёл домой по незнакомой улице.", "Девушка пела в церковном хоре."]
for parse in model(sentences):
print(parse, end="\n\n")
1 Я _ _ _ _ 2 nsubj _ _
2 шёл _ _ _ _ 0 root _ _
3 домой _ _ _ _ 2 advmod _ _
4 по _ _ _ _ 6 case _ _
5 незнакомой _ _ _ _ 6 amod _ _
6 улице _ _ _ _ 2 obl _ _
7 . _ _ _ _ 2 punct _ _
1 Девушка _ _ _ _ 2 nsubj _ _
2 пела _ _ _ _ 0 root _ _
3 в _ _ _ _ 5 case _ _
4 церковном _ _ _ _ 5 amod _ _
5 хоре _ _ _ _ 2 obl _ _
6 . _ _ _ _ 2 punct _ _
As prescribed by UD standards, our model writes the head information to the 7th column and the dependency information – to the 8th. Our parser does not return morphological tags and even does not use them in training.
Model training is done via configuration files, see the configuration file for reference. Note that as any BERT model, it requires 16GB of GPU and the training speed is 1-5 sentences per second. However, you can try less powerful GPU at your own risk (the author himself was able to run the model on 11GB). The inference speed is several hundreds sentences per second, depending on their length, on GPU and one magnitude lower on CPU.
For other usage options see the morphological tagger documentation, the training and prediction procedure is analogous, only the model name is changed.
Joint model usage¶
Our model in principle supports joint prediction of morphological tags and syntactic information,
however, the quality of the joint model is slightly inferior to the separate ones. Therefore we
release a special component that can combine the outputs of tagger and parser:
JointTaggerParser. Its sample output for the
Russian language with default settings
(see the configuration file for exact options)
looks like
from deeppavlov import build_model, configs
model = build_model("ru_syntagrus_joint_parsing", download=True)
sentences = ["Я шёл домой по незнакомой улице.", "Девушка пела в церковном хоре."]
for parse in model(sentences):
print(parse, end="\n\n")
1 Я я PRON _ Case=Nom|Number=Sing|Person=1 2 nsubj _ _
2 шёл идти VERB _ Aspect=Imp|Gender=Masc|Mood=Ind|Number=Sing|Tense=Past|VerbForm=Fin|Voice=Act 0 root _ _
3 домой домой ADV _ Degree=Pos 2 advmod _ _
4 по по ADP _ _ 6 case _ _
5 незнакомой незнакомый ADJ _ Case=Dat|Degree=Pos|Gender=Fem|Number=Sing 6 amod _ _
6 улице улица NOUN _ Animacy=Inan|Case=Dat|Gender=Fem|Number=Sing 2 obl _ _
7 . . PUNCT _ _ 2 punct _ _
1 Девушка девушка NOUN _ Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing 2 nsubj _ _
2 пела петь VERB _ Aspect=Imp|Gender=Fem|Mood=Ind|Number=Sing|Tense=Past|VerbForm=Fin|Voice=Act 0 root _ _
3 в в ADP _ _ 5 case _ _
4 церковном церковный ADJ _ Case=Loc|Degree=Pos|Gender=Masc|Number=Sing 5 amod _ _
5 хоре хор NOUN _ Animacy=Inan|Case=Loc|Gender=Masc|Number=Sing 2 obl _ _
6 . . PUNCT _ _ 2 punct _ _
In the basic case the model outputs a human-readable string with parse data for each information. If you need
to use the output in Python, consult the
class documentation and source code.
Model architecture¶
We use BERT as the lowest layer of our model (the embedder). To extract syntactic information we apply
the biaffine network of [Dozat, Manning, 2017].
For each sentence of length K this network produces two outputs: the first is an array of shape K*(K+1),
where i-th row is the probability distribution of the head of i-th word over the sentence elements.
The 0-th element of this distribution is the probability of the word to be a root of the sentence.
The second output of the network is of shape K*D, where D is the number of possible dependency labels.
The easiest way to obtain a tree is simply to return the head with the highest probability for each word in the sentence. However, the graph obtained in such a way may fail to be a valid tree: it may either contain a cycle or have multiple nodes with head at position 0. Therefore we apply the well-known Chu-Liu-Edmonds algorithm for minimal spanning tree to return the optimal tree, using the open-source modification from dependency_decoding package <https://github.com/andersjo/dependency_decoding>.
Model quality¶
Syntactic parsers are evaluated using two metrics: UAS (unlabeled attachment score), which is the percentage of correctly predicted head positions. The second metric is LAS (labeled attachment score) which treats as positive only the words with correctly predicted dependency label and dependency head.
Dataset |
Model |
UAS |
LAS |
|---|---|---|---|
UD2.3 (Russian) |
UD Pipe 2.3 (Straka et al., 2017) |
90.3 |
89.0 |
UD Pipe Future (Straka, 2018) |
93.0 |
91.5 |
|
UDify (multilingual BERT) (Kondratyuk, 2018) |
94.8 |
93.1 |
|
95.2 |
93.7 |
So our model is by a valuable margin the state-of-the-art system for Russian syntactic parsing.